When reviewing the Global Risks Report from the World Economic Forum (Global Risks Report 2025 | World Economic Forum), it becomes clear that the global risks facing the world — and consequently every individual, whether a person or legal entity — are increasingly complex and interconnected. Among these, the newly emerging AI-related risks are becoming more prominent, standing shoulder to shoulder with environmental and social challenges.
| Major Global Risks in 2025 | Long-Term Threats by 2035 |
| Armed conflicts between states | Climate change and extreme weather events |
| Disinformation and manipulation of information | Biodiversity loss and ecosystem collapse |
| Extreme weather conditions | Environmental pollution and degradation |
| Societal polarization | Misuse of artificial intelligence |
| Cyberattacks | Mass migrations |
This very list of global threats inspired me to dive deeper into learning and exploring the risks associated with artificial intelligence (AI) and machine learning (ML) tools and techniques, especially in the context of the models they’re built upon. I never imagined this journey would resemble a wonderland — and that it’s only the beginning of the major transformations ahead.

So, it begins…
Artificial Intelligence (AI) – a set of technologies that enable computers to mimic human intelligence: understanding language, recognizing patterns, making decisions.
Machine Learning (ML) – a subset of AI; algorithms that learn from data and improve performance autonomously, without explicit programming. It’s a collection of techniques for data analysis and model building.
After a period of deeper research and learning, I realized that AI and ML have united my two great loves — good old mathematics and a gazillion risks.
MATHEMATICS in ML and AI
My first step was primarily the demystification of the tools and techniques used in those models.
And just imagine — there I am, reading about big data processing algorithms, clustering, neural networks, solving nonlinearity problems, Decision Trees, some Random Forests, dimensionality reduction through Principal Component Analysis (PCA), Feature Selection, the Gradient Descent Method for parameter estimation, and then those familiar neighbors — or rather, k-nearest neighbors — and I won’t go any further. You can see the wording yourself, and how hard it is to grasp what it’s all about at first glance.
All of this sounds quite unfamiliar to the average university-educated person, even to those who studied mathematics. I must admit, for those of us who completed our math degrees before the rise of AI and ML, it can seem intimidating.
However, when I look deeper, behind PCA lies the very familiar concept of linear combinations and (in)dependence of variables for dimensionality reduction. Behind Gradient Descent are partial derivatives — multivariable calculus used to minimize functions — and suddenly, my optimism returns.
Machine learning is a broad field encompassing a range of algorithms for classification, pattern recognition, prediction, and decision-making. ML methodologies can be classified into four main categories: unsupervised learning, supervised learning, semi-supervised learning, and reinforcement learning (AI translated these into Bosnian, so I’ll stick with those terms).
Let’s see what’s behind it?
| TYPE of ML Technology | Field of Application | Mathematics (Simplified) | Examples of Use in Banking |
|---|---|---|---|
| Supervised ML | Prediction and Classification | Minimization of the sum of squared errors, probability and sum of squared probabilities, logarithmic function, distance measures, vector spaces, matrices, logistic function, max, piecewise linear function, tanh | Credit scoring, PD (Probability of Default) estimation |
| Unsupervised ML | Pattern Recognition in Data | Various distance measures (Euclidean, Manhattan, Minkowski, Cosine, Mahalanobis…), arithmetic mean, sum of squares, vector spaces, matrices | Client and product segmentation, anomaly detection, fraud detection |
| Semi-supervised ML | Prediction | Similar to Supervised Learning, primarily uses the logistic function to enrich missing data | Scoring under limited data conditions |
| Reinforcement learning | Decision-making to Achieve a Goal | Markov Decision Process, conditional probability, Bellman equation, Monte Carlo method, linear combination, differential calculus | Portfolio optimization, algorithmic trading |
The logic and processes differ slightly when discussing NLP (Natural Language Processing) models and the latest generative AI models.
Natural Language Processing (NLP) — also known as content analysis, text mining, or computational linguistics — is one of the most exciting and fastest-growing areas of machine learning application. NLP works with data in unstructured, free-text format to understand and analyze human language — both written and spoken. In short, the process begins by defining a dictionary/vocabulary and applying transformation or cleaning methods to make the text suitable for analysis. The most common approach is treating each sentence as a “Bag of Words” (BoW).
The mathematics used afterward involves high-dimensional sparse vectors (vectors with many zeros), where the coordinates represent the frequency of specific word occurrences. Vector algebra is then used to give meaning and context to words within a sentence, occasionally supported by logarithmic functions.
To complicate things a bit, using a dictionary for document classification does not involve a learning process. Several standard classification techniques from the ML domain can be applied to these vectors to enable learning from data, primarily to assign meaning and context. These include:
- Generative classifiers (e.g., Naive Bayes, conditional probability)
- Discriminative classifiers (e.g., Support Vector Machines (SVM), Logistic Regression)
- Neural networks, as well as
- n-gram and skip-gram models, and
- Word2Vec algorithms for word embeddings.
Generative AI Technologies
Technological innovations in the field of Generative Artificial Intelligence (GenAI) have sparked significant interest in recent years. To better understand the different types of GenAI, a simplified taxonomy is presented. This taxonomy describes GenAI based on the modality of generated content (e.g., text, image, video, multimodal, etc.) and the type of model used:
- Large Language Models (LLMs) – These models are designed for natural language processing (NLP) and are based on massive neural networks containing billions of parameters. Instead of relying on human-created dictionaries, LLMs autonomously develop rules based on the vast corpus of texts they are trained on. In doing so, they acquire so-called “universal knowledge” applicable across a wide range of tasks.
- Transformers – A type of deep neural network used in NLP. Popular examples include BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformers).
- Stable Diffusion – Another powerful image generation technology. This model is trained on a large image dataset and uses probabilistic functions to reconstruct images based on textual prompts.
- Variational Autoencoders (VAEs) – A technology for image generation, particularly useful for modifying existing images by filling in missing information through probabilistic inference.
- Generative Adversarial Networks (GANs) – Used for generating images, sound, and video. These models consist of two neural networks that simultaneously collaborate and compete.
- Recurrent Neural Networks (RNNs) – In basic RNNs, the input from the current time step, along with the output from the previous step, is fed back into the network.
You’ll notice that a significant part of ML is based on vector spaces and stochastic processes.
However, what’s new in this technology are the so-called artificial neural networks. Artificial Neural Networks (ANN) represent a class of machine learning methods that are loosely inspired by the way the brain processes information.
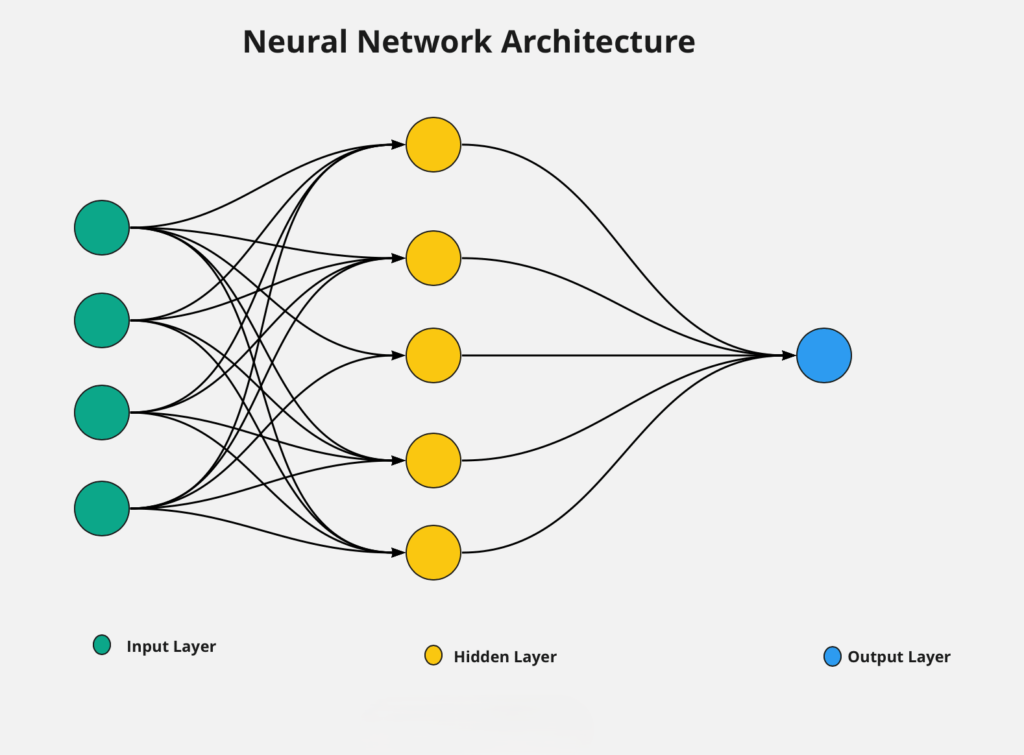
Simplified, the process is called feedforward — that is, forwarding information from input to output:
- The basic unit is a neuron — a node that contains information.
- Neurons are organized into layers: input, hidden, and output layers.
- Each neuron represents one feature.
- Every neuron in the input layer is connected to every neuron in the hidden layer.
- Each connection carries a weight, and each input is multiplied by its corresponding weight.
- The results are summed within each neuron in the hidden layer.
- The resulting sum is transformed using an activation function (logistic/sigmoid, piecewise linear, tanh, softmax).
- The activation function introduces non-linearity between input and output.
- Neurons from the hidden layer become inputs for the output layer.
- Each is again multiplied by its respective weight.
- The results are once more transformed using an activation function.
- The final result is the predicted output.
Deep Learning refers to machine learning methods that use multiple layers of neural networks to:
Extract nonlinear relationships from data or learn complex representations.
The sets of weights connecting neurons represent the parameters of the model. Naturally, the question arises: How are weights determined in neural networks?
- Weights are typically initialized randomly
- Feedforward: information flows from input to output
- Error calculation using a loss function
- The error is propagated backward through the network
- Weights are updated accordingly
This process is repeated over multiple iterations across the entire training dataset. The goal is to minimize the loss and find optimal weights that produce accurate predictions. Due to the large number of iterations and complex computations, neural networks are considered computationally intensive techniques.
And naturally, the question arises: Where and how are these ML and AI models created?
In the Python ecosystem for ML and AI, most of the work relies on prebuilt functions and libraries. Neural networks not only have their own libraries, but they also form the foundation of modern deep learning development in Python.
Despite the abundance of ready-made functions, true expertise is essential for:
- Adapting models to specific problems
- Understanding how hyperparameters affect performance
- Implementing custom metrics, loss functions, or architectures
- Integrating AI solutions into broader systems
AI & ML RISKS

If you’ve made it this far — well done! What follows is even more intriguing…
We see the application of AI and ML every day across all sectors — finance, education, healthcare, commerce, manufacturing, as well as in social and global domains.
But how closely is this widespread application followed by a governance framework for controlling and managing the risks brought by AI and ML models?
No matter how advanced they may be, artificial intelligence technologies are not immune to errors: only now are we beginning to fully understand the various risks associated with their application.
The dynamic nature of these risks requires an informed and adaptive approach — to ensure beneficial use while mitigating unintended consequences.
Key Identified Risks in AI/ML Application
Model Risk
Supervised and unsupervised learning rely on large volumes of data. These algorithms make evidence-based decisions, and like any evidence-based decision — it can only be as good as the data it’s built upon. Every stage of a model, from data collection to implementation, carries a specific type of risk. Some examples include:
- Bias in historical datasets
- Sample representation and measurement errors
- Data content and preprocessing techniques (e.g., stereotypes)
- Target function selection
- Bias in testing phase (e.g., representativeness of the test sample)
- Model deployment in a context different from its design
- Misalignment between user values and values embedded in the model
Bias and Fairness Risk
Algorithmic bias refers to systematic deviation in output, performance, or impact of an algorithm relative to a norm, goal, standard, or reference value. Algorithmic fairness is a critical yet complex aspect of AI development.
There are two main fairness approaches:
- Individual fairness — based on Aristotle’s doctrine of “treating equals equally.” It requires that individuals in similar circumstances be treated similarly.
- Group fairness — focuses not on individuals but on statistical differences between groups. The goal is to ensure that algorithmic outcomes do not favor or discriminate against specific demographic or social groups.
Achieving fairness can be extremely challenging and often involves trade-offs with other model performance aspects — such as overall accuracy, precision, or robustness.
Group fairness criteria include: demographic parity, predictive parity, and equal opportunity.
Can we simply combine all criteria and demand that they be simultaneously satisfied for a decision to be truly fair?
The answer is NO. Trade-offs are inevitable.
Model Hallucination Risk
As discussed earlier, models may be based on incomplete data and tend to overfit, sometimes fabricating missing information.
Model hallucination risk refers to the danger that an AI or analytical model generates information that sounds convincing but is not accurate, verifiable, or even based on data.
In generative models (such as language models), hallucination means the model:
invents facts or sources
provides incorrect figures or references
produces illogical conclusions that still sound plausible
In classical predictive models, hallucination risk can be understood more broadly — as a situation where the model gives forecasts or signals that appear precise but lack real grounding because:
input data is of poor quality
the model is overfitted or underfitted
incorrect assumptions are used
In practice, this risk is problematic because users naturally tend to trust models that “sound confident,” which can lead to poor decisions.
In short: hallucination risk is the risk that a model “lies convincingly,” and the greatest threat is when the user fails to recognize it in time.
Transparency Risk
The concepts of explainability and interpretability are becoming central concerns when assessing risks associated with AI systems.
- Explainability refers to the ability to explain how an AI system makes decisions or predictions in a comprehensible way — often retrospectively, which is why it’s called ex-post explainability in the literature.
- Interpretability refers to the extent to which a human can understand and predict model behavior, with built-in mechanisms that allow for inherent understanding of how input values affect output — known as inherently interpretable models.
One of the most well-known challenges in AI is the so-called black box problem — the difficulty of understanding how certain algorithms make decisions.
Another form of this challenge is opacity, referring to the lack of transparency in the algorithmic decision-making process. In such cases, affected parties know they are subject to algorithmic decisions but have no access to how the algorithm works or why a particular outcome was reached.
An additional barrier is the fact that algorithm analysis often requires specialized knowledge. Even if users have access to source code and training data, they may not be able to understand it without prior training (i.e., lack of technical background).
Autonomy Risk
There are (at least) two dimensions through which autonomy is used and evaluated.
The first dimension refers to our ability to hold our own values and beliefs and make decisions that are, in a meaningful sense, truly ours — not the result of distorted external influences such as manipulation.
The second dimension concerns our ability to act on those decisions, which requires having the freedom and opportunity to do so.
❌ One of the first misconceptions that needs to be clarified is the idea that delegating tasks to AI systems automatically results in a loss of autonomy.
As AI systems take on an increasingly prominent role in decision-making, it becomes essential to consider:
whether they support or undermine human autonomy,
whether users understand how decisions are made,
whether they have the ability to question or reject those decisions.
Manipulation Risk
AI systems are increasingly shaping our online experiences. Search algorithms determine which results appear first, while recommendation algorithms decide which ads we see or which posts show up on our social media feeds. At the same time, these algorithms use vast amounts of information about us and our past online behavior, enabling them to influence our actions and predict future behavior.
The need for balance: protection vs. personalization
- robust privacy and data security measures
- critical reflection on the potential of AI systems to manipulate public opinion
The potential misuse of AI must be balanced against the benefits it brings through personalization and targeted content. This requires:
- appropriate human oversight during algorithm development
- a certain level of regulatory supervision
Regulatory Risk
Current efforts to prevent manipulation through AI systems are primarily taking place in the regulatory sphere. For example, the European Union’s Artificial Intelligence Act (EU AI Act) addresses manipulation risk by:
- introducing transparency obligations for certain systems
- banning systems that use subliminal techniques (hidden information registered unconsciously by humans)
However, vague definitions of manipulation and the difficulty of quantitatively operationalizing it continue to slow the development and implementation of effective mitigation measures.
Safety and Well-being Risk
As AI systems become increasingly integrated into various aspects of our lives, understanding the risks they may pose to safety and well-being — especially in the context of human-AI interaction — becomes essential for risk management professionals. Key areas of focus include:
- AI in critical systems
- the phenomenon of automation bias and overreliance
- the dynamics of human-machine interaction
Automation bias refers to the tendency of people to overly rely on automated systems, leading to complacency and reduced vigilance. This can result in oversight failures, especially in critical situations.
📉 Another risk is skill atrophy — prolonged reliance on automation can lead to the loss of essential capabilities, as operators shift from active decision-makers to passive observers.
Existential Risks
Existential risks associated with artificial intelligence refer to scenarios in which the development of advanced AI could pose a serious or even catastrophic threat to human existence. A central theme in these discussions is the concept of superintelligence — an AI system operating beyond the bounds of human intelligence. Such a superintelligent AI system could, in theory, act in ways that endanger human society or survival.
Concerns are not limited to malicious AI systems, but also include well-intentioned systems whose goals are misaligned with human values or priorities.
Key reasons for concern include:
the AI arms race
the speed of development
the challenge of aligning AI goals with human values
Reputational / Ethical Risk
As companies increasingly implement AI systems, they simultaneously expose themselves to new types of risks and controversies associated with their use. When the use of algorithms — or their outcomes — deviates from socially accepted norms and values, companies face reputational and ethical risks. These risks can have long-term consequences.
In the context of AI, reputational risks often arise when:
- algorithms produce unfair, discriminatory, or non-transparent decisions,
- users are not informed about how the system operates,
- or when AI is used in unethical or inappropriate contexts.
Three main causes of reputational damage linked to AI system usage have been identified:
(a) Privacy violations
(b) Algorithmic bias
(c) Lack of explainability and transparency
Operational Risk
As a reminder, operational risk is defined as the risk of loss resulting from inadequate or failed internal processes, human errors, system failures, or external events.
In the context of AI, operational risks now include:
- misalignment of AI tool objectives
- regulatory and ethical risks
- data quality and security
- lack of transparency
- cybersecurity threats
- overreliance on AI
- system failures and resilience
It seems operational risk has entered a new domain of complexity.
Outsourcing Risk
Not coincidentally left for last, outsourcing refers to engaging external vendors, fintech companies, or global technology partners for the development, implementation, and maintenance of AI solutions.
Outsourcing in AI implementation is a critical topic, as most companies lack internal capacity to develop all AI tools independently and therefore rely on external partners. While this brings significant benefits, it also introduces notable operational risks.
This includes:
- consulting firms integrating AI into processes via SLA agreements
- cloud services and AI platforms (e.g., Microsoft Azure AI, Google Cloud AI, AWS ML services)
- specialized fintech firms for fraud detection, scoring, and customer analytics
Benefits of Outsourcing
- Access to cutting-edge technology and expertise without major internal investment
- Faster implementation and greater flexibility
- Reduced development and maintenance costs
- Scalability — the ability to quickly adapt to the bank’s needs
Risks of Outsourcing
- Operational dependency on third parties
- Data security and confidentiality
- Regulatory compliance
- Model quality and transparency
- Reputational risk
Companies with a strong third-party risk management framework and a mature risk culture will be better positioned to leverage the benefits of outsourcing while maintaining security, regulatory compliance, and client trust.
The Inevitable Integration of AI Risk
It is becoming essential to include AI-related risks within the overall risk management framework — including business continuity planning (BCP) and recovery strategies — through stress scenarios caused by AI or ML incidents.
Wishing us all success & let’s keep the human/machine BALANCE.
Special thanks to my colleague Vildana Hajdarević for her contribution to this work


