

Ako se pogleda Global risk report sa World Economic Foruma Global Risks Report 2025 | World Economic Forum, globalni rizici kojima je svijet izložen a samim tim i svaki pojedinac, bez obzira da li se radi o fizičkom ili pravnom licu, ne može a da se ne primijete novi tzv. emerging AI rizici koji idu rame uz rame sa ekološkim i socijalnim rizicima.
| Najveći globalni rizici u 2025.godini | Dugoročni rizici (do 2035. godine) |
| Oružani sukobi između država | Klimatske promjene i ekstremni vremenski događaji |
| Dezinformacije i manipulacija informacijama | Gubitak biodiverziteta i kolaps ekosistema |
| Ekstremni vremenski uslovi | Zagađenje i degradacija životne sredine |
| Polarizacija društva | Zloupotreba vještačke inteligencije |
| Kibernetički napadi | Masovne migracije |
Primarno me to motiviralo da se više zanimam, učim i istražim o rizicima koji nose AI i ML alati i tehnike u modelima na kojima su bazirani. Nisam ni slutila da će to putovanje biti zemlja čudesa i da je to samo početak velikih transformacija koje slijede.

Da počnemo…
Vještačka inteligencija (AI) – skup tehnologija koje omogućavaju računarima da imitiraju ljudsku inteligenciju: razumiju jezik, prepoznaju obrasce, donose odluke.
Mašinsko učenje (ML) – podskup AI-a; algoritmi koji uče iz podataka i sami poboljšavaju performanse bez eksplicitnog programiranja. To je set tehnika za analizu podataka i izgradnju modela.
Nakon perioda malo dubljeg istraživanja i učenja uvidjela sam da su AI i ML objedinili moje dvije ljubavi, dobru staru matematiku i gazillion rizika.
MATEMATIKA u ML i AI
Prvi korak mi je primarno bila demistifikacija alata i tehnika koje se koriste u tim modelima.
I zamislite čitam tako o algoritmima obrade velikih podataka, klasterizaciji, neuronskim mrežama, rješavanju problema nelinearnosti, Stablima odlucivanja (Decision trees), nekim Nasumičnim šumama (Random Forest), smanjenju dimenzionalnosti analizom glavnih komponenti (PCA Principal Component Analysis) i odabiru karatkeristika (Feature Selection), Gradient Descent Method za procjenu parametara i tu su ti neki najbliži susjedi ili ti komšije (k-nearest neighbors) i da ne idem dalje vidite i vi wording i da je teško razumjet na prvu o čemu se ovdje radi.
Sve ovo zvuči prilično nepoznato za prosječnu fakultetski obrazovanu osobu, koja je i imala matematiku na studijima. Pa moram priznati da za nas koji smo završili studije matematike prije pojave AI i ML izgleda zastrašujuće.
Međutim, kada dublje pogledam iza PCA stoji veoma dobro poznata linearna kombinacija i linearna (ne)zavisnost varijabli za smanjenje dimenzionalnosti, iza Gradient Descent parcijalni izvodi (diferencijalni račun funkcija više promjenljivih za minimizaciju funkcije) i vraća mi se optimizam.
Mašinsko učenje je široka oblast koja obuhvata niz algoritama za klasifikaciju, prepoznavanje obrazaca, predikciju i donošenje odluka. Metodologije mašinskog učenja mogu se klasificirati u četiri glavne kategorije: nenadzirano učenje, nadzirano učenje, polu-nadzirano učenje i učenje putem pojačanja (reinforcement learning) (AI je preveo na bosanski pa cu i koristiti te termine)
Pa da vidimo sta je iza?
| TIP ML Tehnologije | Oblast djelovanja | Matematika (pojednostavljeno) | Neki primjeri primjene u bankarstvu |
|---|---|---|---|
| Nadzirano učenje (Supervised ML) | Predikcija i klasifikacija | Minimizacija sume kvadrata razlike, vjerovatnoća i suma kvadrata vjerovatnoća, logaritamska funkcija, mjere udaljenosti, vektorski prostori, matrice, logisticka funkcija, max, prekidna linearna f-ja, tanh | Kreditno ocjenjivanje, Procjena PD |
| Nenadzirano učenje (Unsupervised ML) | Prepoznavanje obrazaca u podacima | razlicite mjere udaljenosti (Euklidova, Manhattan,Minkowski,Kosinusna, Mahalanobis…), aritmetička sredina, suma kvadrata, vektorski prostori, matrice, | Segmentacija klijenata,proizvoda, otkrivanje anomalija, detekcija prevara |
| Polu-nadzirano učenje (Semi-supervised ML) | Predikcija | Slično kao i za Supervised, koristi uglavnom logističku funkciju da nadogradi nedostajuće podatke. | Scoring u uslovima ograničenih podataka |
| Reinforcement learning | Donošenje odluka radi postizanja cilja | Markovljev proces odlučivanja, uslovna vjerovatnoća, Bellmanova jednačina, Monte Carlo metoda, linearna kombinacija, diferencijalni račun… | Optimizacija portfolija, algoritamsko trgovanje |
Malo se logika i procesi razlikuju kada se govori o NLP (Natural Language Processing) modelima i najnovijim generativnim AI modelima.
Obrada prirodnog jezika (Natural Language Processing – NLP), poznata i kao analiza sadržaja, rudarenje teksta ili kompjuterska lingvistika, predstavlja jedno od najuzbudljivijih i najbrže rastućih područja primjene mašinskog učenja. NLP radi s podacima u nestrukturiranom, slobodnom tekstualnom formatu kako bi razumio i analizirao ljudski jezik – pisani i govoreni. Ukratko, proces počinje definisanjem Rječnika/Vokabulara, metodama transformacije tj. čišćenja da bi tekst bio što pogodniji za analizu, a najčešći pristup jeste tretiranje svake rečenice kao “vreća riječi” (BoW – Bag of Words). Matematika koja se koristi nakon toga su visoko dimenzionalni “rijetki” VEKTORI (vektori sa puno 0) u čije se koordinate smještaju frekvencije pojavljivanja određene riječi. Vektorska algebra se dalje koristi i za davanje smisla i konteksta riječima u rečenici, i eventualno poneka logaritamska funkcija.
Da ne bude baš sve tako jednostavno, korištenje Rječnika za klasifikaciju dokumenata ne uključuje proces učenja. Postoji nekoliko standardnih tehnika klasifikacije iz ML oblasti koje se mogu primijeniti na vektore da bi se dobila neka vrsta učenja na podacima, primarno u svrhu davanja smisla i konteksta: generativni klasifikator (“naivni” Bayesov klasifikator, uslovna vjerovatnoća), diskriminativni (Suport vector machines (SPV), Logistička regresija), Neuronske mreže, zatim n-gram i skip-gram modeli, te Word2Vec algoritmi za ugradnju riječi.
Tehnološke inovacije u oblasti generativne umjetne inteligencije (GenAI) izazvale su veliko interesovanje tokom posljednjih nekoliko godina. Radi boljeg razumijevanja različitih tipova GenAI, predstavlja se pojednostavljena taksonomija. Ova taksonomija opisuje GenAI prema modalitetu generisanog sadržaja (npr. tekst, slika, video, multimodalnost itd.) i prema tipu modela koji se koristi:
- Veliki jezički modeli (Large Language Models – LLM) – LLM-ovi su modeli razvijeni za obradu prirodnog jezika (NLP) i zasnovani su na ogromnim neuronskim mrežama koje sadrže milijarde parametara. Umjesto da koriste rječnike koje su kreirali ljudi, LLM-ovi samostalno razvijaju pravila na osnovu ogromnog korpusa tekstova na kojima su trenirani. Na taj način stiču tzv. „univerzalno znanje“ koje mogu primijeniti na širok spektar zadataka.
- Transformeri – Transformeri su tip dubokih neuronskih mreža (Deep Learning modela) koji se koriste u NLP-u. Popularni primjeri transformera su BERT (bidirekcionalne enkoderske reprezentacije iz transformera) i GPT (Generativni Prethodno-trenirani Transformeri).
- Stable Diffusion – Još jedna moćna tehnologija za generisanje slika je model Stable Diffusion. Ovaj model se trenira na velikoj bazi slika i koristi probabilističke funkcije za rekonstrukciju slike na osnovu tekstualnog upita (prompt).
- Varijacijski autoenkoderi (VAE) – Još jedna tehnologija za generisanje slika. VAE je posebno koristan za modifikaciju postojećih slika jer može popunjavati nedostajuće informacije putem probabilističke inferencije.
- Generativne inverzne mreže (GAN) – koriste za generisanje slika, zvuka i videa. Ovi modeli uključuju dvije neuronske mreže koje istovremeno sarađuju i takmiče se.
- Rekurentne neuronske mreže (RNN) – kod osnovnog RNN-a, ulazi iz trenutnog vremenskog koraka, kao i izlaz iz prethodnog koraka, vraćaju se nazad u mrežu.
Primijetit ćete da se značajan dio ML zasniva na vektorskim prostorima i stohastici.
Medjutim, novo u ovoj tehnologiji jesu takozvane umjetne neuronske mreže. Umjetne neuronske mreže (Artificial Neural Networks – ANN) predstavljaju klasu metoda mašinskog učenja koje su blago inspirisane načinom na koji mozak obrađuje informacije.
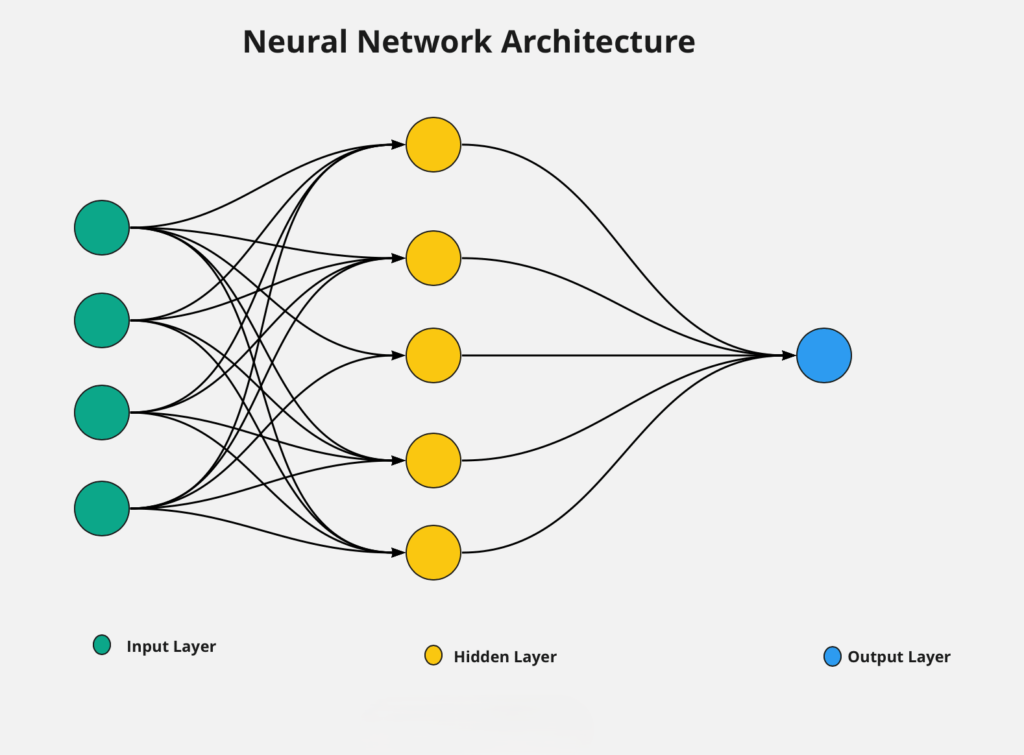
Pojednostavljeno, proces se naziva feedforward — tj. prosljeđivanje informacija od ulaza ka izlazu:
- Osnovna jedinica je neuronski čvor (neuron) — jedinica koja sadrži informaciju.
- Neuroni su organizovani u slojeve (ulazni, skriveni i izlazni sloj)
- Svaki neuron sadrži jednu od karakteristika
- Svaki neuron iz ulaznog sloja je povezan sa svakim neuronom u skrivenom sloju
- Svaka veza nosi težinu i svaki ulaz se množi sa odgovarajućom težinom
- Rezultati se sabiraju u svakom neuronu skrivenog sloja
- Dobijeni zbir se transformiše pomoću aktivacione funkcije (logisticka(sigmoidna), prekidna linearna funkcija, Tanh, Softmax)
- Aktivaciona funkcija unosi nelinearnost u odnos između ulaza i izlaza.
- Neuroni iz skrivenog sloja postaju ulazi za izlazni sloj
- Svaki se množi sa odgovarajućim težinama
- Rezultati se ponovo transformišu pomoću aktivacione funkcije
- Dobijeni rezultat je predikcija izlaza
Duboko učenje (Deep Learning) označava metode mašinskog učenja koje koriste više slojeva neuronskih mreža za: Ekstrakciju nelinearnih odnosa iz podataka ili učenje složenih reprezentacija.
Skupovi težina koji povezuju neurone predstavljaju parametre modela. Prirodno se postavlja pitanje: Kako se u neuronskim mrežama određuju težine?
- Težine se obično nasumično inicijalizuju
- Feedforward
- Izračunavanje greške (loss funkcije)
- Greška se propagira unazad kroz mrežu
- Ažuriranje težina
Proces se ponavlja u više iteracija kroz cijeli trening skup. Cilj je minimizirati gubitak i pronaći optimalne težine koje daju tačne predikcije. Zbog velikog broja iteracija i složenih izračuna, neuronske mreže se smatraju računski intenzivnim tehnikama.
I javlja se prirodno pitanje, gdje se i kako kreiraju ti ML i AI modeli?
U Python ekosistemu za ML i AI, većina rada se zapravo oslanja na gotove funkcije i biblioteke. Neuronske mreže ne samo da imaju svoje biblioteke, već su one temelj modernog razvoja dubokog učenja u Pythonu.
Uprkos obilju gotovih funkcija, stvarna ekspertiza je presudna za:
- prilagođavanje modela specifičnim problemima
- razumijevanje kako hiperparametri utiču na performanse
- implementaciju vlastitih metrika, gubitaka ili arhitektura
- integraciju AI rješenja u šire sisteme
AI & ML RIZICI

Ako ste došli ovdje, svaka čast, interesantno slijedi i u nastavku…
Primjenu AI i ML vidimo svakodnevno u svim oblastima, finansijskoj, edukciji i obrazovanju, u zdravstvu, trgovini i proizvodnji, kao i u društvenim i globalnim i sl…
Koliko zaista primjenu slijedi i upravljački okvir za kontrolu i upravljanje rizicima koje donosi AI i ML modeli?
Koliko god bile napredne, tehnologije vještačke inteligencije nisu imune na greške: tek se sada počinju u potpunosti razumijevati različiti rizici povezane s njihovom primjenom. Dinamična priroda tih rizika zahtijeva da se usvoji informisan i prilagodljiv pristup — kako bismo osigurali korisnu upotrebu, ali i ublažili neželjene posljedice.
Ključni identifikovani rizici u primjeni AI/ML:
Rizik modela
Nadzirano i nenadzirano učenje oslanjaju se na velike količine podataka. Ovi algoritmi donose odluke zasnovane na dokazima, a kao i kod svake odluke zasnovane na dokazima — ona može biti samo onoliko dobra koliko su dobri podaci na kojima se temelji. Svaki stadij modela od prikupljanja podatka do implementacije nosi određenu vrstu rizika. Neki od rizika: Pristrasnost historijskog seta podataka, reprezentacije uzorka, mjerenja, sadržaja podataka, pretprocesnih tehnika (stereotipi), izbor ciljne funkcije, pristrasnost u fazi testiranja (reprezentativnost testnog uzorka), implementacija modela u drugačijem kontekstu od onoga za koji je dizajniran, vrijednost korisnika ne odgovara vrijednosti ugrađenim u model
Rizik pristrasnosti i pravičnosti
Algoritamska pristrasnost je sistemsko odstupanje u izlazu, performansama ili uticaju algoritma u odnosu na neku normu, cilj, standard ili referentnu vrijednost. Algoritamska pravičnost predstavlja ključni, ali istovremeno složen aspekt razvoja vještačke inteligencije.
Postoje dva glavna pristupa pravičnosti: individualna pravičnost i grupna pravičnost.
Individualna pravičnost se oslanja na aristotelovsku doktrinu „jednako postupati s jednakima“. Drugim riječima, ona zahtijeva da se pojedinci u sličnim okolnostima tretiraju jednako.
Grupna pravičnost, s druge strane, ne fokusira se na pojedince, već analizira statističke razlike između grupa. Cilj je osigurati da algoritamski ishodi ne favorizuju ili diskriminišu određene demografske ili društvene grupe.
Postizanje pravičnosti može biti izuzetno izazovno i često podrazumijeva kompromis u drugim aspektima performansi modela — poput ukupne tačnosti, preciznosti ili robusnosti. Kriteriji grupne pravičnosti: demografska ravnoteža, prediktivna ravnoteža i jednake mogućnosti. Možemo li ih jednostavno kombinovati i zahtijevati da svi kriteriji budu zadovoljeni kako bi odluka bila zaista pravična? Odgovor je NE. Kompromisi su neizbježni.
Rizik halucinacije modela
Kao sto smo vidjeli u prethodnom dijelu, modeli mogu biti zasnovani i na nepotpunim podacima, i kao takvi imaju tendeciju pretreniranosti te mogu izmišljati nedostajuće podatke.
Rizik halucinacije modela odnosi se na opasnost da AI ili analitički model generiše informacije koje zvuče uvjerljivo, ali nisu tačne, provjerljive ili uopće zasnovane na podacima.
Kod generativnih modela (poput jezičkih modela) halucinacija znači da model:
> izmišlja činjenice ili izvore,
> daje pogrešne brojke ili reference,
> kreira nelogične zaključke koji se ipak čine uvjerljivima.
Kod klasičnih prediktivnih modela rizik halucinacije može se shvatiti šire – kao situacija kada model daje
prognoze ili signale koji izgledaju precizno, ali nemaju realno utemeljenje jer:
> ulazni podaci nisu kvalitetni,
> model je previše prilagodjen (overfitting/underfitting),
> koristi pogrešne pretpostavke.
U praksi, ovaj rizik je problematičan zato što korisnici imaju prirodnu tendenciju da vjeruju modelu jer on zvuči „sigurno“, te može doći do pogrešnih odluka.
Ukratko: rizik halucinacije je rizik da model “ubjedljivo laže”, a najveća prijetnja je kada korisnik to ne prepozna na vrijeme.
Rizik transparentnosti
Koncepti objašnjivosti i interpretabilnosti postaju centralna briga prilikom procjene rizika povezanih s AI sistemima.
Objašnjivost (explainability) označava sposobnost da se na razumljiv način objasni kako AI sistem donosi odluke ili predikcije, često naknadno — zbog čega se u literaturi naziva „naknadna objašnjivost“ (ex-post explainability).
Interpretabilnost (interpretability) se odnosi na stepen u kojem čovjek može razumjeti i predvidjeti ponašanje modela, uz ugrađene mehanizme koji omogućavaju da se inherentno shvati kako ulazne vrijednosti utiču na izlazne rezultate — poznato kao „inherentno interpretabilni modeli“ (inherently interpretable models).
Jedan od najpoznatijih izazova u oblasti vještačke inteligencije jeste tzv. problem crne kutije (Black box). U srži ovog izazova nalazi se teškoća razumijevanja načina na koji određeni algoritmi donose odluke.
Jedan od oblika jeste i povjerljivost, koja se odnosi na netransparentnost samog procesa algoritamskog odlučivanja. U ovom slučaju, pogođene strane znaju da su podvrgnute algoritamskom odlučivanju, ali nemaju pristup načinu na koji algoritam funkcioniše niti razlozima zašto je određeni ishod postignut.
Još jedna od prepreka jeste činjenica da analiza algoritma često zahtijeva specijalizirano znanje. Čak i ako korisnici imaju pristup izvornom kodu i trening podacima, možda neće biti u stanju da ih razumiju bez prethodne obuke (nedostatka tehničkog predznanja).
Za stručnjake koji se bave upravljanjem rizicima, razumijevanje ovih koncepata je ključno za osiguranje:
transparentnosti
odgovornosti
i povjerenja u AI sisteme
Rizik autonomije
Postoje (najmanje) dvije dimenzije kroz koje se koristi i vrednuje autonomija.
Prva dimenzija odnosi se na našu sposobnost da imamo vlastite vrijednosti, uvjerenja i donosimo odluke koje su u nekom važnom smislu zaista naše — a ne rezultat iskrivljenih vanjskih uticaja, poput manipulacije.
Druga dimenzija odnosi se na našu sposobnost da te odluke sprovedemo, što zahtijeva da imamo slobodu i priliku da to učinimo.
❌ Jedna od prvih zabluda koju treba razjasniti jeste ideja da delegiranjem zadataka AI sistemima automatski gubimo autonomiju.
Kako AI sistemi preuzimaju sve veću ulogu u odlučivanju, postaje ključno razmotriti:
> da li oni podržavaju ili potkopavaju ljudsku autonomiju,
> da li korisnici razumiju kako se odluke donose,
> da li imaju mogućnost da ih preispitaju ili odbace.
Rizik manipulacije
Sistemi vještačke inteligencije sve više oblikuju naše online iskustvo. Algoritmi za pretragu određuju koji rezultati se prikazuju prvi, dok algoritmi za preporuke odlučuju koje oglase vidimo ili koji postovi se pojavljuju na našim društvenim mrežama. Istovremeno, ti algoritmi koriste velike količine informacija o nama i našem prethodnom online ponašanju, što im omogućava da utiču na naše ponašanje i predviđaju naše buduće postupke.
Potreba za ravnotežom: zaštita vs. personalizacija
- robustne mjere zaštite privatnosti i sigurnosti podataka, i
- kritičko razmatranjem potencijala AI sistema da manipulišu javnim mnijenjem.
Potencijalna zloupotreba AI mora se uravnotežiti s koristima koje AI donosi kroz personalizaciju i ciljanje sadržaja, a za to je potrebna:
- adekvatna ljudska kontrola tokom razvoja algoritma,
- kao i određen stepen regulatornog nadzora.
Regulatorni rizik
Trenutni napori za sprječavanje manipulacije putem AI sistema uglavnom se odvijaju u regulatornoj sferi. Na primjer, Akt o vještačkoj inteligenciji Evropske unije (EU AI Act) adresira rizik od manipulacije tako što:
- uvodi obaveze transparentnosti za određene sisteme, i
- zabranjuje sisteme koji koriste subliminalne tehnike (skrivene informacije koje čovjek registruje nesvjesno) na ljudima.
Međutim, nejasna definicija manipulacije i teškoće u njenom kvantitativnom operacionaliziranju i dalje usporavaju razvoj i primjenu efikasnih mjera za ublažavanje rizika.
Rizik sigurnosti i dobrobiti
Kako se sistemi vještačke inteligencije sve više integrišu u različite aspekte našeg života, razumijevanje rizika koje AI može predstavljati za sigurnost i dobrobit, posebno u kontekstu interakcije čovjeka i AI-a, postaje ključno za stručnjake koji se bave upravljanjem rizicima. Obavezan fokus:
- AI u kritičnim sistemima
- fenomen automatizacijske pristrasnosti i pretjeranog oslanjanja,
- te dinamiku interakcije čovjeka i mašine
Automatizacijska pristrasnost označava tendenciju ljudi da se previše oslanjaju na automatizovane sisteme, što dovodi do opuštenosti i smanjene budnosti. To može uzrokovati propuste u nadzoru, naročito u kritičnim situacijama.
📉 Drugi rizik je atrofija vještina — dugotrajno oslanjanje na automatizaciju može dovesti do gubitka ključnih sposobnosti, jer operateri prelaze iz aktivnih donosilaca odluka u pasivne posmatrače.
Egzistencijalni rizici
Egzistencijalni rizici povezani s vještačkom inteligencijom odnose se na scenarije u kojima razvoj napredne AI može predstavljati ozbiljnu ili čak katastrofalnu prijetnju ljudskoj egzistenciji. Centralna tema u ovim raspravama jeste koncept superinteligencije — AI sistema koji djeluje izvan granica ljudske inteligencije. Takav superinteligentni AI sistem bi, teoretski, mogao djelovati na načine koji ugrožavaju ljudsko društvo ili opstanak. Zabrinutost se ne odnosi samo na zlonamjerne AI sisteme, već i na dobronamjerne sisteme čiji ciljevi nisu usklađeni s ljudskim vrijednostima ili prioritetima. Postoji nekoliko razloga za zabrinutosti: Brzina razvoja, problem usklađivanja ciljeva sa ljudskim vrijednostima, trka u naoružanju AI-em. Postoje i argumenti protiv: Trenutno stanje AI-a je jos uvijek “uskog” tipa, povjerenje u regulaciju i upravljanje rizicima, historijsko uporište i iskustvo sa ranijim tehnološkim inovacijama.
Reputacijski/Etički rizik
Kako kompanije sve više implementiraju AI sisteme, istovremeno se izlažu novim vrstama rizika i kontroverzi koje prate njihovu upotrebu. Kada korištenje algoritama — ili njihovi rezultati — odstupe od društveno prihvaćenih normi i vrijednosti, kompanije se suočavaju s reputacijskim i etičkim rizicima. Ovi rizici mogu imati dugoročne posljedice. U kontekstu AI-a, reputacijski rizici se često javljaju kada:
- algoritmi donose nepravedne, diskriminatorne ili netransparentne odluke,
- korisnici nisu informisani o načinu rada sistema,
- ili kada se AI koristi u neetičnim ili neprimjerenim kontekstima.
Pokazano je da tri glavna uzroka reputacijskih šteta povezanih s upotrebom AI sistema jesu:
(a) Povrede privatnosti,
(b) Algoritamska pristrasnost,
(c) Nedostatak objašnjivosti i transparentnosti.
Operativni rizik
Ako se prisjetimo Operativni rizik se definiše kao rizik od gubitka koji nastaje zbog neadekvatnih ili pogrešnih internih procesa, ljudskih grešaka, sistemskih propusta ili vanjskih događaja. Neusklađenost ciljeva AI alata, regulatorni i etički rizici koje donosi, kvalitet i sigurnost podataka koje koristi, nedostatak transparentnosti, cyber sigurnosni rizici, pretjerano oslanjanje ljudi na AI, operativni kvarovi i otpornost sistema predstavljaju neke od ključnih operativnih rizika kod AI rješenja. Ili mi se čini ili su operativni rizici dobili novu zonu djelovanja.
Rizik eksternalizacije
Nije slučajno ostavljen za kraj, Eksternalizacija (outsourcing) koja podrazumijeva angažman vanjskih vendora, fintech kompanija ili globalnih tehnoloških partnera za razvoj, implementaciju i održavanje AI rješenja.
Eksternalizacija u implementaciji umjetne inteligencije je jako važna tema jer većina firmi nema interne kapacitete da same razviju sve AI alate, pa se oslanjaju na vanjske partnere. Sve navedeno nosi velike koristi, ali i značajne operativne rizike te uključuje Konsultantske kompanije za integraciju AI u procese sa SLA ugovorima, Cloud servise i AI platforme (npr. Microsoft Azure AI, Google Cloud AI, AWS ML servisi), Specijalizirane fintech firme za fraud detection, scoring i customer analytics,
Prednosti eksternalizacije
- Pristup najnovijoj tehnologiji i ekspertizi bez velikih internih ulaganja,
- Brža implementacija i fleksibilnost,
- Smanjeni troškovi razvoja i održavanja,
- Skalabilnost – mogućnost brzog prilagođavanja potrebama banke.
Rizici koje eksternalizacija nosi:
- Operativna zavisnost od trećih strana
- Sigurnost i povjerljivost podataka
- Usklađenost sa regulativom
- Kvalitet i transparentnost modela
- Reputacijski rizik
Firme koje imaju snažan okvir upravljanja rizicima eksternalizacije (Third Party Risk Management) i razvijenu kulturu rizika biti će spremne da iskoriste benefite eksternalizacije uz očuvanje sigurnosti, regulatorne usklađenosti i povjerenja klijenata.
Neminovnost postaje uključenje AI rizika u cjelokupan okvir upravljanja rizicima, kao i obradu kroz BCP i druge planove oporavka, kroz stresne scenarije prouzrokovane AI ili ML incidentima.
Nek nam je svima sretno & keep the human/machine BALANCE.
>>Posebnu zahvalnost upućujem kolegici Vildani Hajdarević na doprinosu u dijelu koji se odnosi na operativne rizike i rizike eksternalizacije.<<


